5.5 KiB
\newpage
Vue d'ensemble de Kubernetes
Kubernetes est un système open source d'orchestration et de gestion de conteneurs. C'est-à-dire qu'il se charge de coller constamment aux spécifications qu'on lui aura demandé.
Ce projet est l'aboutissement de plus d'une dizaine d'années d'expérience de gestion de conteneurs applicatifs chez Google (rappelons que c'est eux qui ont poussé de nombreuses technologies dans le noyau Linux, notamment les cgroups, ...).
Dans Kubernetes, il n'est pas question d'indiquer comment lancer ses conteneurs, ni même quels cgroups utiliser. On va fournir à l'orchestrateur des informations, des spécifications qui vont altérer l'état du cluster. Et c'est en cherchant à être constamment dans l'état qu'on lui a décrit, qu'il va s'adapter pour répondre aux besoins.
Par exemple, on ne va pas lui expliquer comment lancer des conteneurs ou récupérer des images ; mais on va lui demander d'avoir 5 conteneurs youp0m lancés, de placer ces conteneurs derrière un load-balancer ; on pourra également lui demander d'adapter la charge pour absorber les pics de trafic (par exemple lors du Black Friday sur une boutique), mais également, il pourra gérer les mises à jour des conteneurs selon différentes méthodes, ...
Architecture de Kubernetes
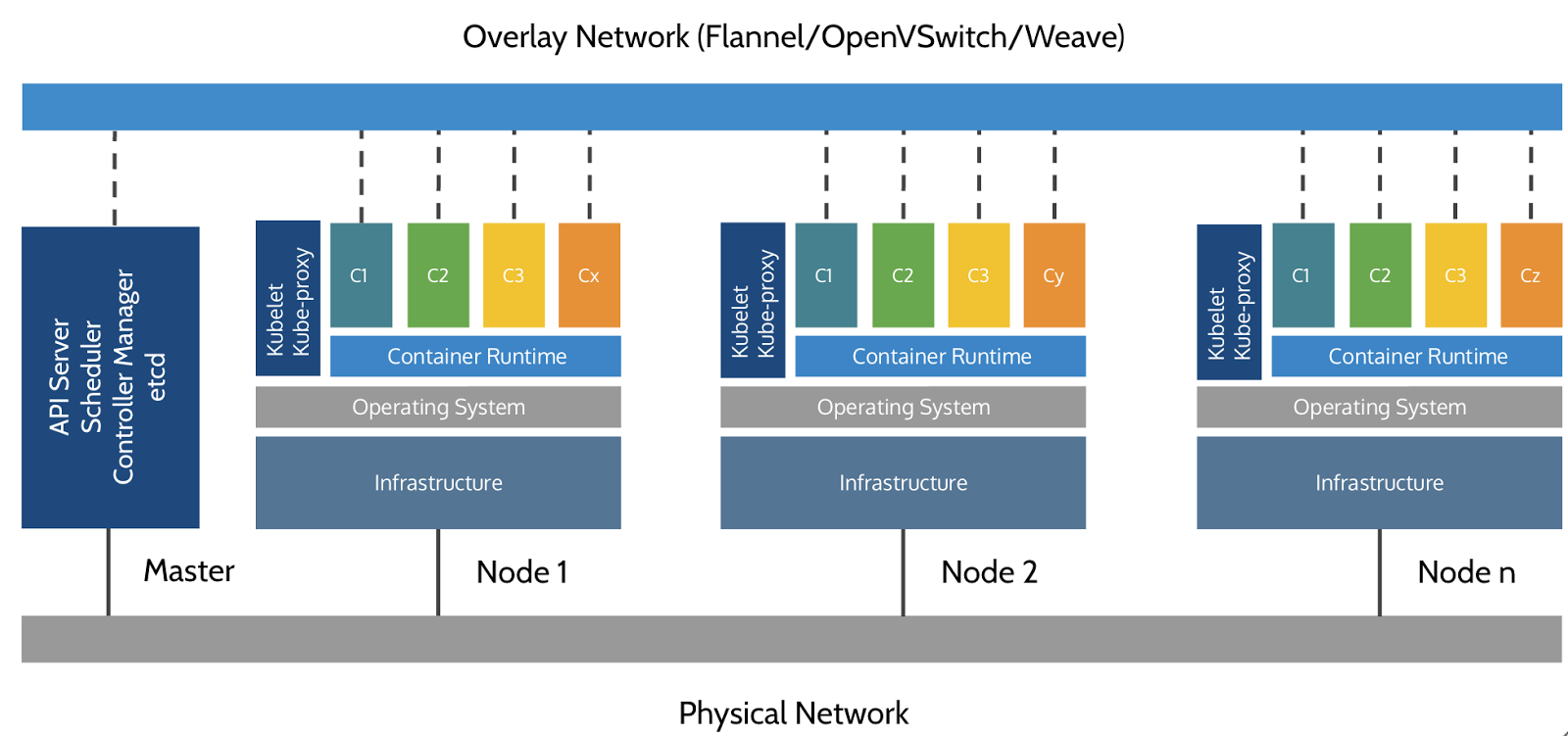
Un cluster Kubernetes est composé d'un (ou plusieurs) nœuds master, et d'une série de workers.
Sur le master, on retrouve les composants suivants :
- API HTTP
- On distingue plusieurs API, elles sont toutes utilisées pour communiquer avec le cluster, pour son administration.
- L'ordonnanceur
- Il a la responsabilité de monitorer les ressources utilisées sur chaque nœud et de répartir les conteneurs en fonction des ressources disponibles.
- Le contrôleur
- Il va contrôler l'état des applications déployées au sein du cluster, pour s'assurer d'être dans l'état désiré.
etcd- Il s'agit d'une base de données clef/valeur, supportant la haute-disponibilité, que Kubernetes emploie comme système de stockage persistant pour les objets d'API.
Chaque nœud1 (généralement, le nœud master est également worker) est utilisé via deux composants :
kubelet- C'est l'agent qui va se charger de créer les conteneurs et les manager, afin de répondre aux spécifications.
kube-proxy- Ce programme va servir de load-balancer pour se connecter aux pods.
Sans oublier le moteur de conteneurs (généralement Docker), qui va
effectivement se charger de lancer les conteneurs demandés par kubelet.
Évidemment, chaque élément de l'architecture est malléable à souhait, c'est la
raison pour laquelle il peut être très difficile de mettre en place une
architecture Kubernetes : avec ou sans haute-disponibilité, un nœud master
dédié au contrôle, avec un moteur de conteneur exotique (rkt, ctr, ...).
Resources
Avec Docker, nous avons eu l'habitude de travailler avec des objets (images, containers, networks, volumes, secrets, ...). Au sein de Kubernetes, cela s'appelle des resources et elles sont très nombreuses.
Parmi les plus courantes, citons les types (désignés Kind dans l'API) suivants :
- node
- il s'agit d'une machine physique ou virtuelle, de notre cluster.
- pod
- un groupe de conteneurs travaillant ensemble. Il s'agit de la ressource que l'on déploie sur un node. Les conteneurs au sein d'un pod ne peuvent pas être séparés pour travailler sur deux nodes différents.
- service
- c'est un point de terminaison (endpoint), stable dans le temps, sur lequel on peut se connecter pour accéder à un ou plusieurs conteneurs. Historiquement, appelés portails/portals, on les retrouve encore quelques fois désignés ainsi dans de vieux articles.
- namespace
- à ne pas confondre avec les namespaces Linux. Ici il s'agit d'espaces de noms divers, pour Kubernetes.
- secret
- comme
docker secret, il s'agit d'un moyen de passer des données sensibles à un conteneur.
Pour voir la liste complète des resources, on utilise : kubectl api-resources.
Modèle réseau
Pour Kubernetes, il n'y a qu'un seul gros réseau au sein duquel se retrouve tous les conteneurs. Il ne doit pas y avoir de NAT, que ce soit entre les pods ou les nodes, chacun doit pouvoir contacter n'importe quel autre élément, sans qu'il y ait de routage.
C'est un modèle assez simpliste au premier abord, mais en raison de la nécessité de faire un minimum de filtrage, de nombreuses extensions viennent compléter ce schéma...
Chaque plugin implémente la spécification CNI (Container Network Interface). On trouve donc autant de plugin qu'il y a de besoins en terme de réseau.
Ainsi, à la création d'un conteneur, Kubernetes va laisser aux plugins CNI le loisir d'allouer l'adresse IP, d'ajouter les interfaces réseaux adéquates, de configurer les routes, les règles de pare-feu, ...
Pour aller plus loin
-
historiquement, avant de parler de node, on parlait de minion. Vous êtes susceptibles de rencontrer encore ce terme dans certaines documentations. ↩︎