3.4 KiB
\newpage
Plusieurs daemons dans un conteneur
Notre système de monitoring commence enfin à ressembler à quelque chose. Mais ce serait tellement plus pratique de voir tous ces tableaux de nombres sous forme de graphiques !
Nous allons pour cela ajouter chronograf dans notre image.
Avant de modifier votre Dockerfile, créez un nouveau dossier de rendu :
mymonitoring, dans lequel vous recopierez l'état actuel de notre image
influxdb.
Chronograf
Commençons par compléter la commande d'installation existante pour influxdb,
afin d'installer simultanément chronograf.
La documentation de la procédure est disponible à cette adresse.
Script d'init
Lors du dernier TP, nous avons vu que les conteneurs s'arrêtaient dès que le
premier processus du conteneur (celui qui a le PID 1, à la place d'init)
terminait son exécution, quelque soit le statut de ses éventuels fils.
Pour lancer tous nos daemons, nous avons donc besoin d'écrire un script qui lance puis attend que les deux deamons aient terminés de s'exécuter.
Écrivons ce script. Hints : wait(1).
\vspace{1em}
Pour vérifier que votre conteneur fonctionne correctement, vous pouvez le lancer :
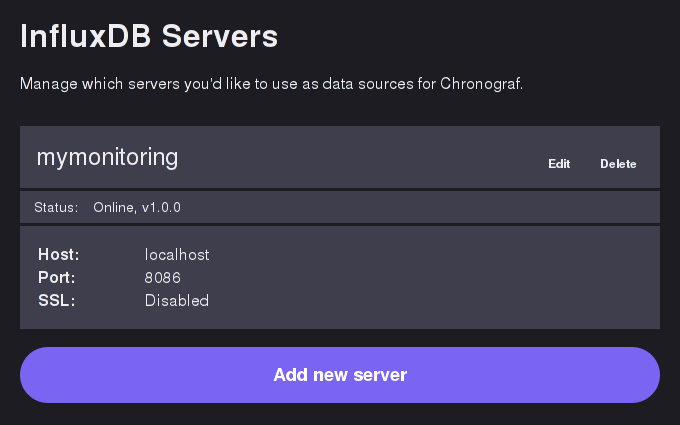
Puis accéder à chronograf : http://localhost:10000/. Donnez un nom à votre configuration, puis cliquez sur Add. Les paramètres préremplis dans le formulaire sont corrects.
Vous devriez obtenir l'écran suivant (notez la partie Status: Online, v1.0.0) :
Autorestart
L'avantage de détruire le conteneur à la mort du père, est que s'il s'agit de
notre processus principal et qu'il est seul (par exemple nginx pour un
conteneur qui délivre des pages web), il va être possible de redémarrer le
conteneur automatiquement grâce à la restart policy que l'on peut définir au
moment du docker run :
Il existe trois règles de redémarrage différentes :
no: il s'agit de la règle par défaut. Lorsque l'exécution du conteneur se termine, il n'est pas redémarré.on-failure[:max-retries]: redémarre uniquement si le code de sortie du conteneur n'est pas 0. Il est possible de préciser pour cette option le nombre maximum de redémarrage qui sera tenté.always: redémarre le conteneur dans tous les cas, quelque soit son code de sortie et indéfiniment.
Le script d'init que vous avez réalisé ne tient sans doute pas compte de
cela. Mais plein de gens ont cette problématique et l'application supervisor
répond parfaitement à notre problématique !
HEALTHCHECK
supervisor
Première étape : installer supervisor, le paquet se trouve dans les dépôts.
L'étape suivante consiste à remplir puis copier le fichier de configuration
dans le conteneur. Vous allez devoir écraser dans votre conteneur le fichier
/etc/supervisord.conf pour démarrer à la fois chronograf et influxdb.
Vous pouvez vous aider de la documentation disponible à : http://supervisord.org/configuration.html
La même procédure de test que précédemment peut être suivie.
Rendu
Nous ne toucherons plus à cette image, placez-la dans un dossier
mymonitoring.