9.3 KiB
Mise en place
La mise en place d'un cluster Kubernetes est une opération qui peut s'avérer très longue et complexe, car comme nous l'avons vu, elle nécessite l'installation et la configuration de nombreux composants avant de pouvoir être utilisé pleinement.
Cette installation n'étant pas très palpitante (c'est beaucoup de lecture de documentations et d'heures passées à essayer de faire tomber en marche tous les composants d'un seul coup), nous ne la verrons pas ici.
D'ailleurs, dans les milieux professionnels, il est plutôt rare de voir des entreprises investir dans la gestion de leur propre cluster Kubernetes. La plupart des entreprises qui font le choix d'utiliser Kubernetes pour gérer leurs infrastructures, choisissent de passer par un prestataire. L'entreprise délègue donc la gestion de son/ses cluster(s) à une autre entreprise, dont c'est le cœur de métier. La plupart du temps, il va s'agir d'Amazon (via Elastic Kubernetes Service), d'Azure Kubernetes Service) ou Google (Kubernetes Engine), mais d'autres acteurs plus petits existent aussi (OVHcloud, ...).
::::: {.more}
Lorsque l'on veut créer son cluster, on a le choix d'assembler tous les composants de Kubernetes soi-même (vanilla), ou alors de partir d'une distribution existante. On parle de distribution dans le même sens que l'on connaît les distributions GNU/Linux : chacun peut aller récupérer les sources du noyau Linux et des différents programmes nécessaires au démarrage et à l'exécution d'un système d'exploitation fonctionnel, ou alors on peut utiliser une distribution qui met à notre disposition un noyau Linux et tout un écosystème de programmes qui forment un système d'exploitation cohérent et qui fonctionne.\
Chaque distribution de Kubernetes aura donc pris soin de mettre à disposition des composants pour un usage plus ou moins spécifique. En dehors des composants strictement nécessaires qui ne changent pas, on verra d'une distribution à l'autre des choix quant au moteur d'exécution de conteneurs (tantot CRI-O, Containerd, KataContainers, ...), le réseau sera géré par une brique spécifique (Flannel, Calico, Canal, Wave, ...), le stockage peut également faire l'objet de choix.\
Devant la complexité de conception et le nombre grandissant de distributions, une certification est délivrée aux distributions sérieuses. On en dénombre tout de même plus d'une cinquantaine1.\
Pour l'IoT ou l'Edge Computing, sur du matériel léger, il existe le projet k3s2 : il s'agit d'une distribution Kubernetes beaucoup plus simple à déployer, et parfaitement adaptée à la production sur Raspberry Pi et autres.
:::::
Pour jouer, plusieurs solutions s'offrent à nous pour commencer à utiliser Kubernetes facilement :
- Docker Desktop (for Mac ou for Windows) : si vous êtes sur l'un de ces systèmes c'est la solution la plus simple,
- Kubernetes in Docker (kind) : pour tenter l'aventure sur votre machine,
- Play With Kubernetes : si vous ne vous en sortez pas avec
kind.
Docker for Mac/Windows
Docker Desktop pour Mac ou pour Windows intègre Kubernetes directement. Il n'est pas activé par défaut, pour cela il convient d'activer l'option dans les préférences de l'application :
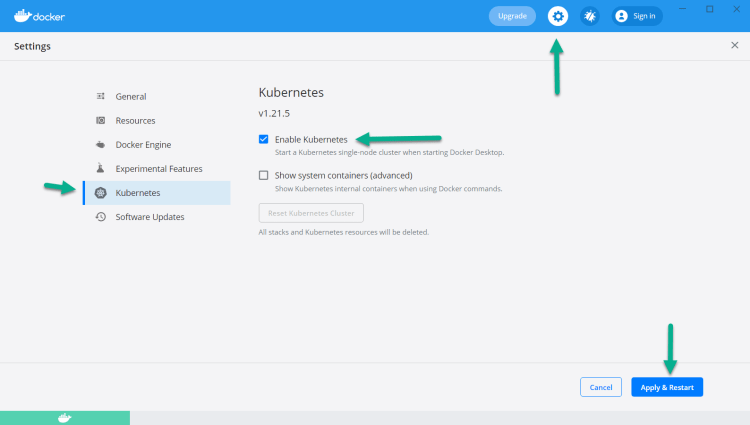
Une fois l'option activée, vous pouvez passer au chapitre suivant, la commande
kubectl devrait marcher directement pour vous. C'est principalement grâce à
cette commande que nous interagirons avec l'API de Kubernetes.
Une fois que tout sera opérationnel, nous devrions obtenir :
Kubernetes in Docker (kind)
kind est un projet permettant de lancer un cluster Kubernetes directement via
Docker.
Pour commencer, il nous faudra télécharger le binaire (go, donc statique) suivant (il existe pour Linux, macOS et Windows) :
https://github.com/kubernetes-sigs/kind/releases/latest
Placez le binaire (chmod +x {}) dans un endroit où il sera accessible de
votre $PATH.
Notre prochaine étape est de décrire le cluster que l'on souhaite avoir : 1 control-plane et 2 workers, ça fera l'affaire. Attention tout de même à ne pas être trop extravagant, car chaque nœud consomme pas mal de RAM ! Et puis nous pourrons facilement changer cette configuration plus tard.
La création du cluster peut prendre quelques minutes.
Profitons-en pour télécharger kubectl :
https://storage.googleapis.com/kubernetes-release/release/v1.25.3/bin/linux/amd64/kubectl
C'est principalement grâce à cette commande que nous interagirons avec l'API de Kubernetes.
Une fois que tout sera opérationnel, nous devrions obtenir :
Par défaut, kubectl va tenter de contacter le port local 2375, kind aura
pris soin de l'exposer pour vous au moment de la création du cluster.
::::: {.warning}
S'il vous manque la ligne Server et que les commandes kubectl
échouent, c'est que la configuration de l'accès à l'API du cluster n'a
pas été faite. Vous pouvez écraser la configuration avec :
:::::
Passez ensuite au chapitre suivant si vous avez réussi à mettre en place kind.
Play With Kubernetes
::::: {.warning}
Cette section vous concerne uniquement si vous n'avez pas réussi à créer de cluster Kubernetes selon les autres méthodes décrites.
:::::
De la même manière que pour les exercices utilisant Docker, si vous avez des difficultés pour réaliser les exercices sur vos machines, vous pouvez utiliser le projet Play With K8s qui vous donnera accès à un bac à sable avec lequel vous pourrez réaliser tous les exercices.
Il nous faut créer plusieurs instances, disons 3 : parmi elles, 1 instance sera pour notre control-plane, que nous utiliserons principalement, les deux autres ne feront qu'exécuter des conteneurs, nous pourrons les oublier dès qu'on les aura connectées à notre nœud principal.
Pour initialiser notre cluster Kubernetes, nous allons commencer par créer le contrôleur. Pour cela, dans notre première instance, nous allons taper :
Cette action peut prendre quelques minutes et devrait se finir, si tout se passe bien, par :
To start using your cluster, you need to run (as a regular user):
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node as root:
kubeadm join --token TOKEN IPADDRESS --discovery-token-ca-cert-hash SHAHASH
</div>
Recopions ensuite la commande `kubeadm join ...` donnée dans le terminal, dans
nos deux autres instances. Cela permettra aux machines de se connecter au
master.
Dernière étape pour la mise en place de notre cluster, il s'agit de définir un
plugin de modèle réseau, sur le nœud principal (nous n'exécuterons plus de
commande sur les autres *workers*) :
<div lang="en-US">
```bash
kubectl apply -f \
https://raw.githubusercontent.com/cloudnativelabs/kube-router/master/daemonset/kubeadm-kuberouter.yaml
Minikube, k3d, MicroK8s, ...
Si les solutions précédentes ne sont pas adaptées à votre usage, de nombreuses autres applications permettent de mettre en place un cluster plus ou moins complet facilement.
Vous pouvez tenter d'utiliser k3d, minikube, microk8s, ...
k3d {-}
est un script similaire à kind, mais utilise k3s, une version plus légère
et compacte de Kubernetes.
Après l'avoir installé, vous pouvez lancer :
-
Voir la liste sur https://www.cncf.io/certification/software-conformance/. ↩︎
-
Lightweight Kubernetes : https://k3s.io/ ↩︎